Time Series Changes and Versioning with TimeDB
This notebook demonstrates how to update values, tags, and annotations and view all versions:
Flat series — in-place updates for fact data (no versioning)
Overlapping series — versioned updates with full audit trail
Flexible update lookups — using
batch_id,known_time, or justvalid_timeReading all versions — query history with
read(versions=True)
[1]:
from timedb import TimeDataClient
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime, timezone, timedelta
import numpy as np
from dotenv import load_dotenv
load_dotenv()
td = TimeDataClient()
td.delete()
td.create()
Creating database schema...
✓ Schema created successfully
Part 1: Insert Time Series (Flat and Overlapping)
First, let’s insert two time series:
Flat series:
meter_reading- for fact data that can be corrected in-placeOverlapping series:
temperature- for estimates/forecasts with version history
For the overlapping series, we’ll insert TWO batches to demonstrate versioning:
Batch 1: Initial forecast (known_time = 00:00)
Batch 2: Revised forecast (known_time = 02:00) with slightly different values
This means each valid_time will have 2 versions before we even start updating!
[2]:
# Create time series with hourly data for 24 hours
base_time = datetime(2025, 1, 1, 0, 0, tzinfo=timezone.utc)
times = [base_time + timedelta(hours=i) for i in range(24)]
# Generate sample data
np.random.seed(42)
temperature_values = [
round(20.0 + 5.0 * np.sin(2 * np.pi * i / 24) + np.random.normal(0, 0.5), 2)
for i in range(24)
]
meter_values = [round(100.0 + i * 5.0 + np.random.normal(0, 0.2), 2) for i in range(24)]
df_temp = pd.DataFrame({'valid_time': times, 'value': temperature_values})
df_meter = pd.DataFrame({'valid_time': times, 'value': meter_values})
# Create series
if td.series("meter_reading").count() == 0:
td.create_series(name="meter_reading", unit="dimensionless")
if td.series("temperature").count() == 0:
td.create_series(name="temperature", unit="dimensionless", overlapping=True)
for s in td.series().list_series():
print(f" {s['name']}: overlapping={s['overlapping']}")
# Insert flat series
result_flat = td.series("meter_reading").insert(df=df_meter)
print(f"\nInserted FLAT: meter_reading (series_id={result_flat.series_id})")
# Insert TWO batches for overlapping series to demonstrate versioning
known_time_1 = base_time
result_batch_1 = td.series("temperature").insert(df=df_temp, known_time=known_time_1)
print(f"Inserted OVERLAPPING Batch 1 (known_time={known_time_1}, batch_id={result_batch_1.batch_id})")
known_time_2 = base_time + timedelta(hours=2)
temperature_values_revised = [round(v + np.random.normal(0, 1.0), 2) for v in temperature_values]
df_temp_revised = pd.DataFrame({'valid_time': times, 'value': temperature_values_revised})
result_batch_2 = td.series("temperature").insert(df=df_temp_revised, known_time=known_time_2)
print(f"Inserted OVERLAPPING Batch 2 (known_time={known_time_2}, batch_id={result_batch_2.batch_id})")
# Store IDs for later use
batch_id_1 = result_batch_1.batch_id
batch_id_2 = result_batch_2.batch_id
series_id_temp = result_batch_1.series_id
series_id_meter = result_flat.series_id
print(f"\nEach valid_time now has 2 versions in the overlapping series.")
meter_reading: overlapping=False
temperature: overlapping=True
Inserted FLAT: meter_reading (series_id=1)
Inserted OVERLAPPING Batch 1 (known_time=2025-01-01 00:00:00+00:00, batch_id=1)
Inserted OVERLAPPING Batch 2 (known_time=2025-01-01 02:00:00+00:00, batch_id=2)
Each valid_time now has 2 versions in the overlapping series.
Part 2: Read and Plot the Time Series
Let’s read back both time series and visualize them.
For the overlapping series, read() returns the latest version (highest known_time), which is Batch 2. Use read(versions=True) to see all versions.
[3]:
# Read both time series
# For overlapping, read() returns the LATEST version (highest known_time)
df_temp_read = td.series("temperature").read(
start_valid=base_time,
end_valid=base_time + timedelta(hours=24),
)
df_meter_read = td.series("meter_reading").read(
start_valid=base_time,
end_valid=base_time + timedelta(hours=24),
)
print(f"Temperature (overlapping, latest version): {len(df_temp_read)} data points")
print(f"Meter reading (flat): {len(df_meter_read)} data points")
# Also read ALL versions to see both batches
df_temp_all_versions = td.series("temperature").read(
start_valid=base_time,
end_valid=base_time + timedelta(hours=24),
versions=True, # Get ALL versions
)
print(f"\nTemperature (all versions): {len(df_temp_all_versions)} data points")
print(f" (24 hours x 2 batches = 48 rows)")
print(f"\nIndex levels: {df_temp_all_versions.index.names}")
# Show a sample of the multi-version data
print("\nSample of all versions (first 6 rows):")
df_temp_all_versions.head(6)
Temperature (overlapping, latest version): 24 data points
Meter reading (flat): 24 data points
Temperature (all versions): 48 data points
(24 hours x 2 batches = 48 rows)
Index levels: ['known_time', 'valid_time']
Sample of all versions (first 6 rows):
[3]:
| value | ||
|---|---|---|
| known_time | valid_time | |
| 2025-01-01 00:00:00+00:00 | 2025-01-01 00:00:00+00:00 | 20.25 |
| 2025-01-01 01:00:00+00:00 | 21.22 | |
| 2025-01-01 02:00:00+00:00 | 22.82 | |
| 2025-01-01 03:00:00+00:00 | 24.30 | |
| 2025-01-01 04:00:00+00:00 | 24.21 | |
| 2025-01-01 05:00:00+00:00 | 24.71 |
[4]:
# Plot both time series
fig, axes = plt.subplots(2, 1, figsize=(12, 8), sharex=True)
# Temperature (overlapping series) - show BOTH forecasts
ax1 = axes[0]
# Get both versions from df_temp_all_versions
for known_time in df_temp_all_versions.index.get_level_values('known_time').unique():
df_version = df_temp_all_versions.xs(known_time, level='known_time')
temp_y = df_version['value'].astype(float)
label = f"Forecast {known_time.strftime('%H:%M')}"
ax1.plot(df_version.index.get_level_values('valid_time'), temp_y,
marker='o', linewidth=2, markersize=5, alpha=0.7, label=label)
ax1.set_ylabel('Temperature', fontsize=11)
ax1.set_title('Temperature (Overlapping) - Both Forecast Versions', fontsize=12, fontweight='bold')
ax1.legend()
ax1.grid(True, alpha=0.3)
# Meter reading (flat series)
ax2 = axes[1]
meter_y = df_meter_read['value'].astype(float)
ax2.plot(df_meter_read.index, meter_y, marker='s', linewidth=2, markersize=5,
color='green', alpha=0.7)
ax2.set_ylabel('Meter Reading', fontsize=11)
ax2.set_xlabel('Time', fontsize=11)
ax2.set_title('Meter Reading (Flat) - In-Place Updates', fontsize=12, fontweight='bold')
ax2.grid(True, alpha=0.3)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
print("✓ Both time series plotted successfully!")
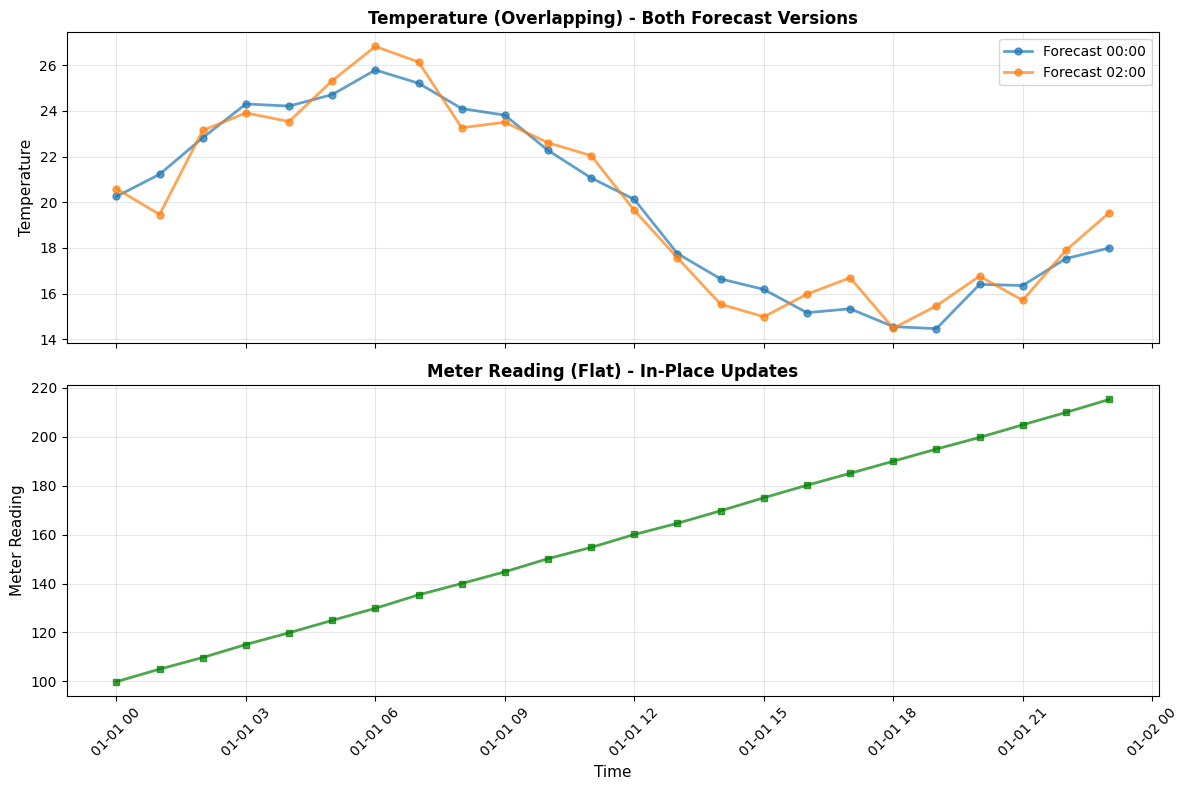
✓ Both time series plotted successfully!
Part 3: Update a Flat Series (In-Place)
Flat series use in-place updates - there’s no version history. The value is simply replaced.
This is ideal for correcting fact data like meter readings where you want to fix errors without maintaining a version trail.
[5]:
# Update a flat series - simple, no batch_id needed!
update_time_flat = base_time + timedelta(hours=5)
# Read current value
original_meter_value = float(df_meter_read.loc[update_time_flat, 'value'])
print(f"Original meter reading at {update_time_flat}: {original_meter_value:.2f}")
# Update the flat series - just need series_id and valid_time!
corrected_meter_value = 130.0
result = td.series("meter_reading").update_records(updates=[{
"valid_time": update_time_flat,
"value": corrected_meter_value,
"annotation": "Corrected: faulty meter reading",
"changed_by": "technician@example.com",
}])
print(f"\nFlat update completed!")
print(f" Updated: {original_meter_value:.2f} -> {corrected_meter_value:.2f}")
print(f" Updated records: {len(result)}")
# Verify the update - read it back
df_meter_after = td.series("meter_reading").read(
start_valid=update_time_flat,
end_valid=update_time_flat + timedelta(hours=1),
)
print(f"\nVerification - current value: {float(df_meter_after.iloc[0]['value']):.2f}")
Original meter reading at 2025-01-01 05:00:00+00:00: 124.94
Flat update completed!
Updated: 124.94 -> 130.00
Updated records: 1
Verification - current value: 130.00
Part 4: Update Overlapping Series (Versioned)
Overlapping series create new versions on each update - the old value is preserved with its original known_time.
Since we now have two batches (two versions per valid_time), we can demonstrate three ways to identify which version to update:
Using ``batch_id``: Target the latest version within a specific batch
Using ``known_time``: Target an exact version by its known_time
Using just ``valid_time``: Target the latest version overall (most convenient!)
[6]:
# We'll update three different time points using each method
update_time_1 = base_time + timedelta(hours=6) # Method 1: batch_id
update_time_2 = base_time + timedelta(hours=12) # Method 2: known_time
update_time_3 = base_time + timedelta(hours=18) # Method 3: just valid_time
# Show current values before updates
print("Current values BEFORE updates:\n")
for ut in [update_time_1, update_time_2, update_time_3]:
versions = df_temp_all_versions.xs(ut, level='valid_time')
print(f" {ut}:")
for known_time, row in versions.iterrows():
kt = known_time if not isinstance(known_time, tuple) else known_time[0]
print(f" known_time={kt}: {float(row['value']):.2f}")
# METHOD 1: Update using batch_id (targeting Batch 1)
print(f"\nMETHOD 1: batch_id — update {update_time_1} in Batch 1")
result_1 = td.series("temperature").update_records(updates=[{
"batch_id": batch_id_1,
"valid_time": update_time_1,
"value": 29.0,
"annotation": "Updated via batch_id (targeting Batch 1)",
"tags": ["method_batch_id"],
"changed_by": "demo@example.com",
}])
print(f" Updated {len(result_1)} record (new version with known_time=now())")
# METHOD 2: Update using known_time (exact version lookup)
print(f"\nMETHOD 2: known_time — update {update_time_2} from Batch 1 (known_time={known_time_1})")
result_2 = td.series("temperature").update_records(updates=[{
"known_time": known_time_1,
"valid_time": update_time_2,
"value": 27.0,
"annotation": "Updated via known_time (exact version from Batch 1)",
"tags": ["method_known_time"],
"changed_by": "demo@example.com",
}])
print(f" Updated {len(result_2)} record")
# METHOD 3: Update using just valid_time (latest version)
print(f"\nMETHOD 3: valid_time only — update latest version at {update_time_3}")
result_3 = td.series("temperature").update_records(updates=[{
"valid_time": update_time_3,
"value": 25.0,
"annotation": "Updated via latest lookup (most convenient!)",
"tags": ["method_latest"],
"changed_by": "demo@example.com",
}])
print(f" Updated {len(result_3)} record")
Current values BEFORE updates:
2025-01-01 06:00:00+00:00:
known_time=2025-01-01 00:00:00+00:00: 25.79
known_time=2025-01-01 02:00:00+00:00: 26.82
2025-01-01 12:00:00+00:00:
known_time=2025-01-01 00:00:00+00:00: 20.12
known_time=2025-01-01 02:00:00+00:00: 19.64
2025-01-01 18:00:00+00:00:
known_time=2025-01-01 00:00:00+00:00: 14.55
known_time=2025-01-01 02:00:00+00:00: 14.48
METHOD 1: batch_id — update 2025-01-01 06:00:00+00:00 in Batch 1
Updated 1 record (new version with known_time=now())
METHOD 2: known_time — update 2025-01-01 12:00:00+00:00 from Batch 1 (known_time=2025-01-01 00:00:00+00:00)
Updated 1 record
METHOD 3: valid_time only — update latest version at 2025-01-01 18:00:00+00:00
Updated 1 record
Part 5: View All Versions (Version History)
Now let’s read the overlapping series with versions=True to see all versions:
Original Batch 1 values
Revised Batch 2 values
Our new update versions (with
known_time=now())
[7]:
# Read all versions for the time points we updated
df_versions = td.series("temperature").read(
start_valid=base_time + timedelta(hours=5),
end_valid=base_time + timedelta(hours=20),
versions=True,
)
print("All versions AFTER updates:\n")
for ut, method in [(update_time_1, 'batch_id'), (update_time_2, 'known_time'), (update_time_3, 'valid_time')]:
print(f"Valid time: {ut} (updated via {method})")
try:
versions = df_versions.xs(ut, level='valid_time')
for idx, row in versions.iterrows():
known_time = idx if not isinstance(idx, tuple) else idx[0]
value = float(row['value'])
if known_time == known_time_1:
source = "Batch 1 (original)"
elif known_time == known_time_2:
source = "Batch 2 (revised)"
else:
source = "UPDATE (new version)"
print(f" known_time={known_time} -> {value:.2f} [{source}]")
except KeyError:
print(f" No data for this time point")
print()
print("Each update created a NEW version with known_time=now().")
print("The original Batch 1 and Batch 2 values are preserved.")
All versions AFTER updates:
Valid time: 2025-01-01 06:00:00+00:00 (updated via batch_id)
known_time=2025-01-01 00:00:00+00:00 -> 25.79 [Batch 1 (original)]
known_time=2025-01-01 02:00:00+00:00 -> 26.82 [Batch 2 (revised)]
known_time=2026-02-15 21:47:59.350862+00:00 -> 29.00 [UPDATE (new version)]
Valid time: 2025-01-01 12:00:00+00:00 (updated via known_time)
known_time=2025-01-01 00:00:00+00:00 -> 20.12 [Batch 1 (original)]
known_time=2025-01-01 02:00:00+00:00 -> 19.64 [Batch 2 (revised)]
known_time=2026-02-15 21:47:59.358713+00:00 -> 27.00 [UPDATE (new version)]
Valid time: 2025-01-01 18:00:00+00:00 (updated via valid_time)
known_time=2025-01-01 00:00:00+00:00 -> 14.55 [Batch 1 (original)]
known_time=2025-01-01 02:00:00+00:00 -> 14.48 [Batch 2 (revised)]
known_time=2026-02-15 21:47:59.366116+00:00 -> 25.00 [UPDATE (new version)]
Each update created a NEW version with known_time=now().
The original Batch 1 and Batch 2 values are preserved.
Part 6: Visualize Original vs Updated
Let’s plot both versions to see the changes visually.
[8]:
# Read current (latest) version after all updates
df_current = td.series("temperature").read(
start_valid=base_time,
end_valid=base_time + timedelta(hours=24),
)
# Also read Batch 1 and Batch 2 values for comparison
# We can get them by reading all versions and filtering
df_all = td.series("temperature").read(
start_valid=base_time,
end_valid=base_time + timedelta(hours=24),
versions=True,
)
# Plot comparison
plt.figure(figsize=(14, 7))
# Extract values from each batch
batch1_values = []
batch2_values = []
for vt in times:
try:
versions = df_all.xs(vt, level='valid_time')
for kt, row in versions.iterrows():
known_time = kt if not isinstance(kt, tuple) else kt[0]
if known_time == known_time_1:
batch1_values.append(float(row['value']))
elif known_time == known_time_2:
batch2_values.append(float(row['value']))
except KeyError:
pass
# Plot Batch 1 (original)
plt.plot(times, batch1_values,
marker='o', linewidth=1.5, markersize=4,
label=f'Batch 1 (known_time={known_time_1.strftime("%H:%M")})',
color='blue', alpha=0.5, linestyle='--')
# Plot Batch 2 (revised)
plt.plot(times, batch2_values,
marker='s', linewidth=1.5, markersize=4,
label=f'Batch 2 (known_time={known_time_2.strftime("%H:%M")})',
color='orange', alpha=0.5, linestyle='--')
# Plot current (latest after updates)
current_y = df_current['value'].astype(float)
plt.plot(df_current.index, current_y,
marker='D', linewidth=2.5, markersize=6,
label='Current (latest after updates)', color='red', alpha=0.9)
# Highlight the updated points
for ut, label, color in [
(update_time_1, 'batch_id update', 'green'),
(update_time_2, 'known_time update', 'purple'),
(update_time_3, 'valid_time update', 'brown')
]:
plt.axvline(x=ut, color=color, linestyle=':', linewidth=2, alpha=0.7)
# Add annotation
plt.annotate(label, xy=(ut, plt.ylim()[1]), xytext=(5, -10),
textcoords='offset points', fontsize=8, rotation=90, va='top')
plt.xlabel('Valid Time', fontsize=12)
plt.ylabel('Temperature (dimensionless)', fontsize=12)
plt.title('Time Series Versioning: Batch 1 vs Batch 2 vs Updates', fontsize=14, fontweight='bold')
plt.legend(loc='upper right', fontsize=9)
plt.grid(True, alpha=0.3)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
print("Dotted lines mark the three updated time points (hours 6, 12, 18)")
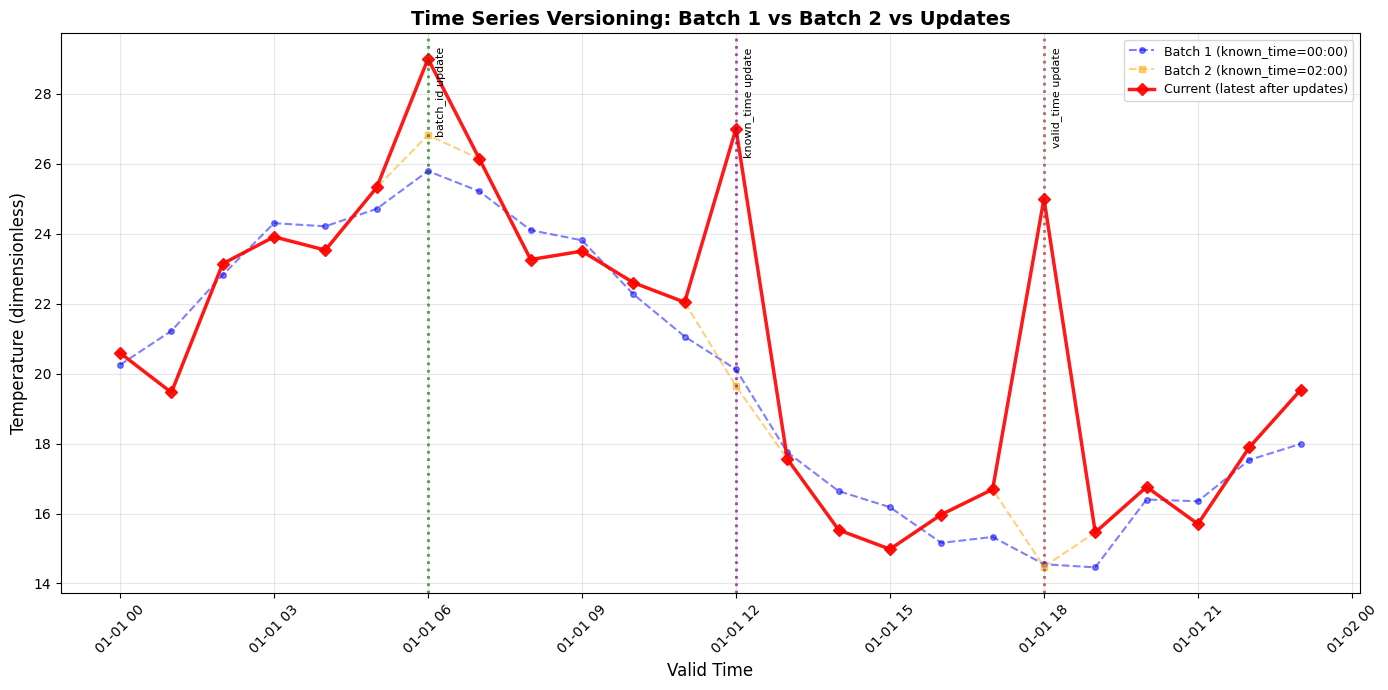
Dotted lines mark the three updated time points (hours 6, 12, 18)
Summary
Flat series: in-place updates via
td.series("name").update_records(updates=[{"valid_time": dt, "value": ...}])Overlapping series: versioned updates — creates new row with
known_time=now(), preserving originalsThree lookup methods for overlapping:
batch_id,known_time, or justvalid_time(targets latest)Read versions:
read(versions=True)returns full audit trail with(known_time, valid_time)indexUpdateable fields:
value,annotation,tags,changed_by